Machine Learning has been around for decades starting with academic research in the 1950s. While there were important theoretical advances and applications, widespread commercial adoption of ML was slow until the 2010s. But as talent became more available, open-source software libraries matured, and compute became cheaper, we saw a Cambrian Explosion of startups and enterprises using ML to augment business and build intelligent products.
My mental framework breaks these companies down into three different types of teams: those building ML models used to solve a problem, those building tools for ML engineers, and those engaged in deep research work.
ML Appliers
I used to be an ML engineer at an AI startup called Suited. We built machine learning models to predict candidate job performance at large-scale professional services firms (investment banks, law firms, etc.). We were what I call “ML Appliers” – we built machine learning models to solve a particular problem for our customers. ML Appliers say we have a problem. Let’s use ML algorithms to solve that problem. This is an extremely broad characterization that describes everything from self-driving cars to predictive hiring. There are important structural similarities across ML Appliers though. Here are a few:
- ML Appliers don’t engage in primary research, but rather train already implemented algorithms. You mostly experiment with a menu of well-understood algorithms that meet your requirements. Primary research is mostly delegated to academia or the advanced R&D department of a big tech firm.
- ML problems require clear performance metrics to optimize – if you’re building a product recommendation engine, you maximize sales for the products you recommend. If you’re building a machine translator, you match human translations.
- Everyone deals with annoying data engineering.
- All ML Appliers are data hungry. They will not say no to additional higher quality, training data nor to add predictive features. While there are theoretical diminishing returns to marginal data points, this rarely occurs in the real world. Data becomes stale and irrelevant.
ML Appliers Competitive Moat
Point #4 is especially important – companies that are able to amass plenty of high-value proprietary data sets tend to outcompete because they can build high-quality models. The best ML Appliers are able to design a positive feedback loop. A high-value ML model leads to more user engagement leading to more user data and a better ML model.[1] This is exactly how Google’s search engine became the best in the world, and if you optimize for the wrong thing, Facebook became a disinformation hellscape.
ML also shares a similar quality as other technologies– solutions to hard technical problems are natural barriers to entry. Even if all of Tesla’s data landed in someone’s lap, it would be extremely difficult to recreate the self-driving car. Even if you had all of Google’s Search Data, you’re still decades behind in domain expertise to compete head-on on search quality. The engineering complexity alone would be cost-prohibitive.
Without those two things, engineering complexity and propriety high-value data, ML solutions tend to get commoditized quickly. We’ve seen this in Optical Character Recognition (OCR) and eCommerce Product Recommendation Engines, with dozens of companies in each space.
Here’s my rough sketch of how the ML Applier landscape looks right now.
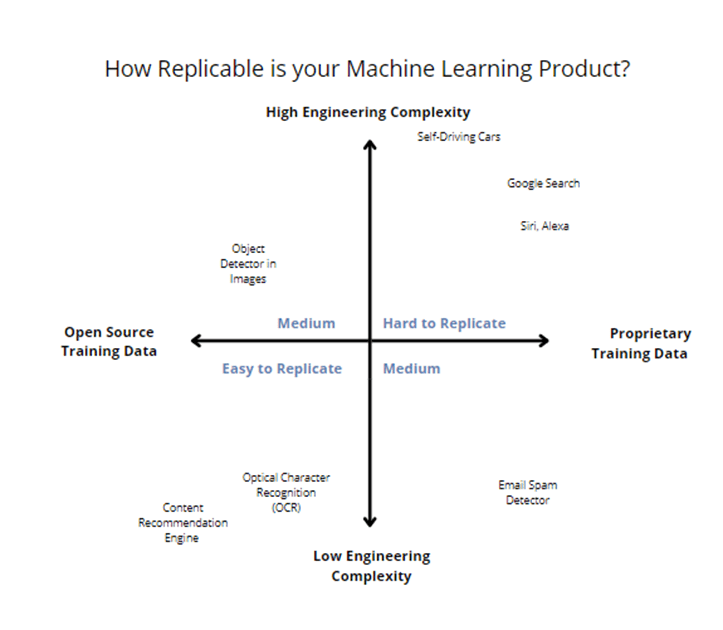
I’ll dig deeper into how ML Appliers can create sustainable competitive advantages in future posts
MLOps
Historically, machine learning work was highly customized for a specific use case. ML Appliers would need to, at a minimum follow these steps:
- Write queries to extract the relevant data from the database (ETL phase)
- Write data transformation scripts to munge the data into the correct format (ETL phase)
- Select a model type. See how well it works.
- Repeat Steps 2 and 3 until you reach an acceptable accuracy threshold.
- Build an API around that model so that model’s results can be consumed by other systems.
- Deploy to production
There were many of problems with this process – model builders aren’t software engineers; they’re researchers. They hack together scripts to see what works. Building production systems is hard; maintaining and monitoring them is even harder. Also, ML models are not purely deterministic like other software. Every time you train a model, you might get a slightly different result. This results in serious reproducibility concerns. You will probably also have data/model versioning issues – what if you change the query in Step 1 slightly? What if the underlying training data change?
These sorts of issues contribute to extraordinarily long deployment timelines (sometimes over a year for a single model) and high failure rates of ML projects. As recently as 2019, Venture Beat reports that 87% of data science projects never make it to production[AP2] .
The MLOps movement arose to address these problems. MLOps applied DevOps style thinking to ML projects, building tools to accelerate data extraction, model training, and model deployment. Companies started to popup that made each step in the process easier
Here is a great graphic that shows a breakdown of the MLOps landscape.

Rise of End-to-End MLOps Solutions?
The landscape above is very fragmented. It is annoying to port data across different systems. This naturally, has led to some companies trying to consolidate all these tools into a single platform. After doing just a quick search, I was able to find:
- Dataiku
- Cnvrg.io
- BaseTen
- Valohai
Each of these solutions has its own pros and cons and there is yet to be an established market leader. I suspect this is because even end-to-end companies have invested differently in different stages of the model-building life cycle. Company A might have a really good model deployment module while Company B does a lot better on feature engineering.
I will note though, that I don’t think all companies will eventually be on an end-to-end platform. Some use cases will be so specialized that an out-of-the-box solution would be foolhardy. High-Frequency Trading Firms, for instance, will always have their own specialized research & deployment architectures because of their extreme speed requirements.
Deep Research
These are the people pushing the cutting edge of machine learning. The archetypal deep researcher is the Ph.D. student or professor who comes up with an interesting new algorithm. Many of the most popular and powerful ML algorithms today started as papers published by academics (Backpropagation, Artificial Neural Networks, LSTMs, etc). These teams don’t commercialize their work, but many of the most prominent AI researchers at universities migrate to industry.
A final organization type under this category includes the deep research companies – OpenAI and Google’s DeepMind. It’s difficult to categorize these companies. They’re three-parts research lab, one-part commercial enterprise. Basically, these companies are trying to solve Artificial General Intelligence. However, they still have some revenue generating activities. DeepMind, well known for building AlphaGo, also helps Google design better products and cut costs in its data centers. OpenAI, the developer of the GPT line of language models, has paid APIs to apply the models to a variety of different tasks.
Conclusion
ML is an extremely exciting field full of intense activity. While enterprise adoption grows (sluggishly), many startups are becoming “ML native” and adopting machine learning techniques from their inception. It’s clear that ML is no long niche and as the ecosystem develops, we’ll see accelerated adoption.
[1] This depends on the ML model providing enough value to the customer. Just incorporating ML isn’t enough to create a sustainable competitive advantage.
